【コスト最適化AI開発】cc-sdd×ccccで実現する仕様駆動マルチエージェント開発

1. はじめに
1.1. 最近のAIコーディングの課題
1.1.1. コンテキスト喪失 (Context Loss)
〜「さっき言ったよね?」が通じなくなる瞬間〜
- 現象 :
- プロジェクトが進行し、コードベースが大きくなるにつれて、AIが初期の設計方針や命名規則を無視し始める。
- 「
utils.pyのあの関数を使って」と指示しても、新しく似たような関数を勝手に再実装してしまう(コードの重複)。 - 修正を依頼すると、以前修正したはずのバグが復活する(デグレ)。
- 原因 :
- トークンウィンドウの限界 : LLMは一度に扱える情報量に物理的な限界があります。会話が長引くと、最初の方に定義した「重要なアーキテクチャの制約」がウィンドウ外に押し出され、AIの短期記憶から消滅します。
- 注意機構(Attention)の希薄化 : 入力情報が増えすぎると、AIが「今本当に重要な指示」に集中できなくなり、局所的な修正に終始して全体整合性を破壊します。
1.1.2. 役割の曖昧さ (Role Ambiguity)
〜「万能選手」を目指して、器用貧乏に陥る〜
- 現象 :
- 1つのAIエージェントに「アプリを作って」と投げると、設計・実装・テスト・修正をすべて1回の回答で行おうとする。
- 高コストな失敗 : 最高性能のモデルが、本来なら安価なモデルでも書けるような「大量のボイラープレートコード(import文や定型的なgetter/setter)」の生成にトークンを浪費する。
- 低品質な意思決定 : 実装の細部に気を取られ、「このクラス設計で拡張性は担保できるか?」といった高レイヤーの視点が欠落する。
- 原因 :
- 役割分担による品質向上のためccccと組み合わせて使用 : 人間の開発チームでも「PM」と「プログラマ」が分かれているように、本来これらは異なる思考モード(拡散思考と収束思考)が必要です。これを1つのコンテキストで混ぜてしまうと、AIは「コードを書くこと」に引きずられ、「設計を考えること」がおろそかになります。
1.1.3. 仕様ドリフト (Specification Drift)
〜「動くけど、これじゃない」ものが出来上がる〜
- 現象 :
- 実装中に技術的な壁にぶつかった際、AIがユーザーに相談なく 仕様を勝手に変更して解決してしまう。
- 例:「OAuth認証の実装が複雑だったので、簡易的なBasic認証にしておきました」
- ドキュメント(設計書)とコード(実装)が徐々に乖離し、最終的には「ソースコードしか真実を知らない」という保守不可能な状態になる。
- 実装中に技術的な壁にぶつかった際、AIがユーザーに相談なく 仕様を勝手に変更して解決してしまう。
- 原因 :
- 報酬設計の罠 : 現在のLLMは「ユーザーの指示(タスク)を完了させること」を最優先にします。「仕様書を守ること」よりも「エラーなくコードを動かすこと」へのバイアスがかかりやすいため、安易な(しかし仕様違反の)解決策を選びがちです。
- フィードバックループの欠如 : 実装したコードが「元の設計意図」と合致しているかを機械的にチェックする仕組み(バリデーション)がないため、ズレが検知されないまま開発が進んでしまいます。
1.2. 解決策としての「仕様駆動開発」と「マルチエージェント協調」
前述した課題を解決するために、今回は2つの強力なアプローチを導入しました。
1.2.1. 仕様駆動開発 (SDD) で「正解」を外部化する
〜AIの記憶力に頼らない〜
仕様ドリフトやコンテキスト喪失を防ぐ唯一の方法は、「正解(Single Source of Truth)」をチャットログの外に置くこと です。
- ドキュメント・ファースト : いきなりコードを書かせるのではなく、まずはMarkdown形式の仕様書(要件定義、設計、タスク)を生成させます。
- アンカー効果 : 実装中にAIが迷っても、常に「仕様書」というアンカー(錨)に戻ることで、文脈を見失うことを防ぎます。
- 検証可能性 : 「仕様書通りに動くか?」という客観的なテストが可能になり、品質が担保されます。
これを実現するツールとして、今回は cc-sdd を採用しました。

1.2.2. マルチエージェント協調で「役割」を分業する
〜1人で悩ませない、チームで戦う〜
「器用貧乏」なAIを作らないためには、人間の組織と同じく「役割分担(Role Definition)」 が有効です。
- Architect (設計者) : 全体最適を考え、指示を出すことに特化。コードの細部は見ない。
- Builder (実装者) : 与えられた小さなタスクを、エラーなく実装することに集中。全体設計には口を出さない。
- Foreman (監督者) : 2人が作業に没頭している間、冷静に全体進捗と品質を監視する。
この分業体制を自動でオーケストレーションするために、cccc を採用しました。
ccccについては、こちらの記事を参考にしました。

2. キーテクノロジーの紹介
2.1. cc-sdd について (The Architect)
2.1.1. 概要
cc-sdd は、仕様駆動開発 (Spec-Driven Development, SDD) をAI開発環境で実現するためのオープンソースCLIツールです。Amazon Web Services (AWS) の内部ツール "Kiro" にインスパイアされ、Claude Code、Cursor、GitHub Copilot CLI など、多様なAIエージェントと連携して動作します。
2.1.2. 役割:なぜ「Architect」なのか?
これまでのAIコーディングは、チャットベースの「対話」が主体でした。しかし、複雑なシステム開発では、対話だけでは文脈(コンテキスト)を維持できず、仕様の抜け漏れや矛盾が生じやすくなります。
cc-sdd は、AIにいきなりコードを書かせるのではなく、まずは「設計(Thinking)」に集中させる 役割(Architect)を担います。人間の曖昧なアイデアをヒアリングし、構造化されたドキュメント(Markdown)として出力することで、実装フェーズに渡す「正解」を定義します。
2.1.3. 特徴的な機能 (Key Features)
- Steering (ステアリング / Project Memory) :
- プロジェクトの技術スタック、命名規則、アーキテクチャ方針などを
.kiro/steering/に「プロジェクトメモリ」として蓄積します。これにより、AIは常にプロジェクトの文脈を理解した上で、一貫性のある提案を行うようになります。
- プロジェクトの技術スタック、命名規則、アーキテクチャ方針などを
- Spec-Driven Workflow (仕様駆動ワークフロー) :
- Requirements : EARS形式などのフォーマットで、曖昧さを排除した要件定義書 (
requirements.md) を作成。 - Design : アーキテクチャ図やAPI定義、データモデルを含む詳細設計書 (
design.md) を生成。 - Tasks : 実装手順を依存関係や並列性を考慮して分解したタスクリスト (
tasks.md) を出力。
- Requirements : EARS形式などのフォーマットで、曖昧さを排除した要件定義書 (
- Quality Gates (品質ゲート) :
/kiro:validate-implなどのコマンドにより、実装されたコードが設計書と矛盾していないかを機械的に検証します。これにより、AIによる「勝手な仕様変更(Spec Drift)」を物理的に防ぎます。
2.1.4. 【重要】なぜ実装機能を使わないのか?
cc-sdd は本来、/kiro:spec-impl コマンドを使用して、AIによるコード生成とテスト実行までを一貫してサポートしています。
しかし、今回のアーキテクチャでは、この実装機能をあえて使用しません。
- 単独ツールの限界 :
cc-sdd単体での実装は優秀ですが、単一のエージェントが作業を行うため、「思い込みによるミス」や「自己完結的な修正」が発生するリスクがあります。 - ccccへの委譲 : 実装フェーズを
ccccに任せることで、「PeerA(指示)とPeerB(実装)による相互レビュー(Dual-Peer Check)」 という強力な品質担保プロセスを強制的に組み込むことができます。
つまり、cc-sdd には「最高のArchitect」であることに専念してもらい、実装は「最強のBuilderチーム(cccc)」に任せるという適材適所(Best-of-Breed)のアプローチ を採用しています。
2.2. cccc について (The Builder)
2.2.1. 概要
cccc (CCCC Pair) は、2つのAIエージェント(Peer)が対等なパートナーとして協力し、自律的にタスクを遂行する「デュアルAIオーケストレーター」です。 従来の「AIと人間がペアプログラミングする(Copilot型)」ツールとは異なり、「AIとAIがペアプログラミングし、人間はそれを監督する(Manager型)」 という新しい開発体験を提供します。
2.2.2. 役割:なぜ「Builder」なのか?
設計書(Spec)があっても、それを実装する段階では多くの「試行錯誤」が必要です。エラーの修正、環境依存の問題解決、エッジケースの対応……これらを1つのAIで行うと、視野が狭くなり(Tunnel Vision)、品質が低下します。
cccc は、「実装(Do)」と「レビュー(Check)」を2つのAIに分担させる ことで、人間の介入なしに自律的に品質を高める「Builder(実装者)」としての役割を果たします。
2.2.3. 特徴的な機能 (Key Features)
- Dual-Peer Architecture (デュアルピア・アーキテクチャ) :
- PeerAとPeerBが Mailbox という非同期通信メカニズムで連携し、お互いの作業をブロックすることなく並行して思考・作業できます。
- 本来の設計思想 : デフォルトでは、PeerAとPeerBは「対等なパートナー(Equal Peers)」として定義されており、どちらも設計・実装・レビューを行うことができます。
- Foreman (自律監督システム) :
- Peerたちが作業に没頭している間、バックグラウンドで独立して稼働する「現場監督」エージェントです。
- 定期的(デフォルト15分毎)に
FOREMAN_TASK.mdに書かれた監視タスク(ビルド確認、スモークテストなど)を実行し、問題があれば即座にPeerたちに警告(Nudge)を飛ばします。
- Evidence-First Workflow (エビデンス駆動) :
ccccの哲学は「言葉ではなく証拠」です。AIが「直しました」と言っても、テストログや実行結果(Evidence)が提示されない限り、タスクは完了とみなされません。
2.2.4. 【重要】今回の構成における戦略的カスタマイズ
cccc の標準では2体は「対等」ですが、本プロジェクトではあえて明確な上下関係(役割分担)を設定 しました。
- PeerA(指示役 / Lead Architect) :
- 使用モデル : Claude Opus などの高性能・高コストモデル 。
- 役割 : 全体の方針決定、設計の整合性チェック、PeerBへの的確な指示出し。
- 制約 : 「コードを極力書かない」ことを強制し、トークン消費を抑えます。
- PeerB(実装役 / Lead Engineer) :
- 使用モデル : GPT-4o-mini / Haiku などの軽量・低コストモデル 。
- 役割 : PeerAの指示に基づくコーディング、テスト作成、ファイル操作などの大量のテキスト生成。
なぜこの構成なのか?(コスト最適化) AI開発において、最もトークン(コスト)を消費するのは「コードの出力」です。 高度な推論能力を持つ高価なモデル(PeerA)には「思考」のみを担当させ、単純なコード生成や修正といった「作業」は安価なモデル(PeerB)に任せることで、開発品質を最高レベルに保ちつつ、運用コストを削減 することを目的としています。
2.3. TUI (Text User Interface)
ターミナルを4分割し、PeerA/PeerBの思考プロセス、システムログ、全体のタイムラインをリアルタイムで可視化します。
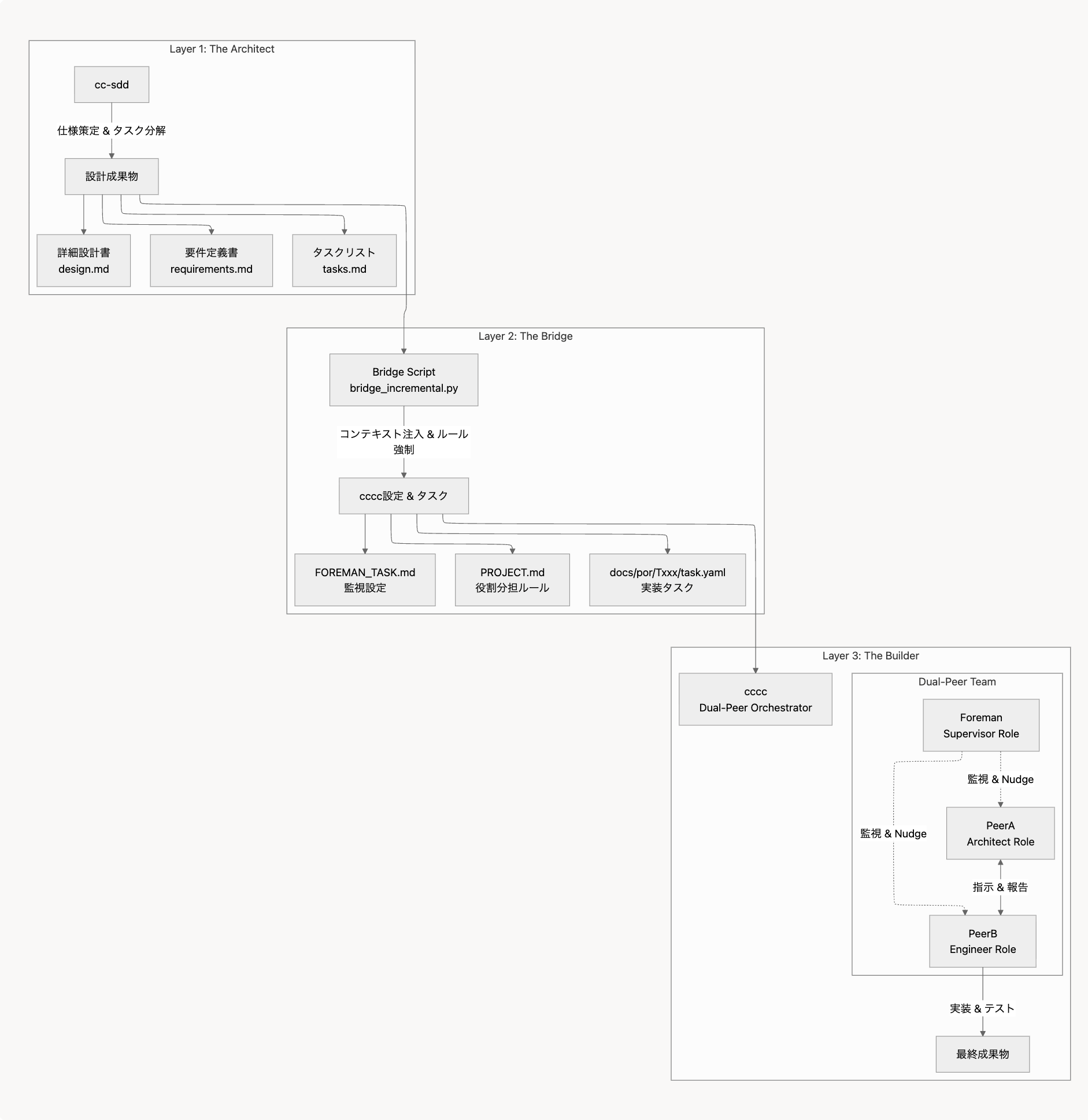
3. システムアーキテクチャ概要
- Layer 1: Architect層 (
cc-sdd): 仕様策定とタスク分解 - Layer 2: Bridge層 (Python Script) : コンテキスト注入とルール強制
- Layer 3: Builder層 (
cccc): 実装と検証(Dual-Peer)
Layer 1のcc-sddのアウトプットをLayer 3のccccのインプットとするために、Layer 2のPythonスクリプトにて自動的に変換します。
sequenceDiagram
actor User as 👤 ユーザー
participant CC as cc-sdd<br/>(Architect)
participant Bridge as bridge_incremental.py<br/>(Bridge)
participant CCCC as cccc orchestrator
participant PeerA as PeerA<br/>(高性能モデル)
participant PeerB as PeerB<br/>(低コストモデル)
participant Foreman as Foreman<br/>(監督者)
participant Validate as validate-impl<br/>(検証)
Note over User,Validate: Phase 1: 設計フェーズ (Design Phase)
User->>CC: /kiro:spec-init<br/>(プロジェクト概要)
CC-->>User: steering情報を生成
User->>CC: /kiro:spec-requirements
CC->>CC: 要件定義書を生成
CC-->>User: requirements.md
User->>CC: 承認します
User->>CC: /kiro:spec-design
CC->>CC: 設計書を生成
CC-->>User: design.md
User->>CC: 承認します
User->>CC: /kiro:spec-tasks
CC->>CC: タスクリストを生成
CC-->>User: tasks.md
User->>CC: 承認します
Note over User,Validate: Phase 2: ブリッジ変換 (Bridge Transformation)
User->>Bridge: python bridge_incremental.py
Bridge->>Bridge: requirements.md読み込み
Bridge->>Bridge: design.md読み込み
Bridge->>Bridge: tasks.md読み込み
Bridge->>Bridge: 役割分担ルール生成
Bridge->>Bridge: 監視設定生成
Bridge->>Bridge: T000挿入
Bridge-->>User: PROJECT.md<br/>FOREMAN_TASK.md<br/>docs/por/Txxx/
Note over User,Validate: Phase 3: 自律実装フェーズ (Autonomous Implementation)
User->>CCCC: cccc run
CCCC->>CCCC: TUI起動・モデル選択
User->>PeerA: /a docs/por/T000から実行して
rect rgb(255, 240, 240)
Note over PeerA,Foreman: T000: 環境設定タスク
PeerA->>PeerA: プロジェクト環境調査
PeerA->>PeerB: FOREMAN_TASK.mdを<br/>実際のコマンドで更新して
PeerB->>PeerB: pytest, python3コマンド確認
PeerB->>PeerB: FOREMAN_TASK.md更新
PeerB-->>PeerA: 完了報告
end
loop 各タスク (T001-T028)
rect rgb(240, 255, 240)
Note over PeerA,PeerB: 実装サイクル
PeerA->>PeerA: 設計意図を整理<br/>(コード生成禁止)
PeerA->>PeerB: 実装指示<br/>(擬似コード・方針)
PeerB->>PeerB: コーディング
PeerB->>PeerB: テスト実行
PeerB->>Validate: npx cc-sdd /kiro:validate-impl
Validate-->>PeerB: 仕様整合性チェック結果
alt 検証成功
PeerB-->>PeerA: 実装完了報告<br/>(Evidence付き)
PeerA->>PeerA: レビュー
PeerA-->>User: タスク完了
else 検証失敗
PeerB->>PeerA: エラー報告
PeerA->>PeerB: 修正指示
end
end
par バックグラウンド監視
Foreman->>Foreman: 15分毎にチェック実行
Foreman->>Foreman: pytest実行
Foreman->>Foreman: スモークテスト
alt 問題検出
Foreman->>PeerA: 🚨 ALERT
Foreman->>PeerB: 🚨 ALERT
end
end
end
Note over User,Validate: Phase 4: 完成・検証
PeerB->>User: 全タスク完了通知
User->>User: 最終動作確認
User->>User: 成果物確認4. 環境構築と実行
4.1. ツール群のセットアップ
4.1.1. cc-sddのセットアップ
今回はcursorにて利用可能な環境を構築します。
プロジェクトのディレクトリ内で次のコマンドを実行します。
npx cc-sdd@latest --cursor --lang ja4.1.2. ccccのセットアップ
プロジェクトのディレクトリ内で次のコマンドを実行します。
brew install tmux
pip install pipx # if you don't have pipx
pipx install cccc-pair
cccc init今回はcursorを利用するため、.cccc/settings/agents.yamlに次のコードを追加します。これによりcccc実行時に使用するcursorのモデルを指定しやすくなります。
cursor-sonnet:
# Cursor CLI with sonnet-4.5-thinking model (for PeerA)
peer:
command: "cursor-agent --model sonnet-4.5-thinking"
input_mode: "paste"
post_paste_keys: ["Enter"]
send_sequence: "Enter"
idle_quiet_seconds: 1.0
prompt_regex: ''
busy_regexes: []
aux:
invoke_command: 'cursor-agent --model sonnet-4.5-thinking -p "Read .cccc/rules/AUX.md first. {prompt}"'
rate_limit_per_minute: 2
foreman:
invoke_command: 'cursor-agent --model sonnet-4.5-thinking -p "{prompt}"'
compact:
enabled: true
command: "/compress"
capabilities: "Cursor AI agent with sonnet-4.5-thinking; strong coding; editor-integrated experience"
env_require: []
cursor-composer:
# Cursor CLI with composer-1 model (for PeerB)
peer:
command: "cursor-agent --model composer-1"
input_mode: "paste"
post_paste_keys: ["Enter"]
send_sequence: "Enter"
idle_quiet_seconds: 1.0
prompt_regex: ''
busy_regexes: []
aux:
invoke_command: 'cursor-agent --model composer-1 -p "Read .cccc/rules/AUX.md first. {prompt}"'
rate_limit_per_minute: 2
foreman:
invoke_command: 'cursor-agent --model composer-1 -p "{prompt}"'
compact:
enabled: true
command: "/compress"
capabilities: "Cursor AI agent with composer-1; strong coding; editor-integrated experience"
env_require: []
cursor-auto:
# Cursor CLI with auto model (automatic model selection)
peer:
command: "cursor-agent --model auto"
input_mode: "paste"
post_paste_keys: ["Enter"]
send_sequence: "Enter"
idle_quiet_seconds: 1.0
prompt_regex: ''
busy_regexes: []
aux:
invoke_command: 'cursor-agent --model auto -p "Read .cccc/rules/AUX.md first. {prompt}"'
rate_limit_per_minute: 2
foreman:
invoke_command: 'cursor-agent --model auto -p "{prompt}"'
compact:
enabled: true
command: "/compress"
capabilities: "Cursor AI agent with auto model selection; strong coding; editor-integrated experience"
env_require: []4.2. 設計フェーズ (The Architect)
cc-sddを利用し、Task一覧を定義することを目的としています。
cc-sddの詳細は割愛しますが、どのようなプログラムを作成するか提示することで、AIと対話しながら仕様を決定し、タスクに分解していきます。
4.2.1. プロジェクト概要設定
cc-sddのコマンドでプロジェクト概要を設定します。
シンプルなMarkdown to HTML変換CLIツール。
## 機能要件
- 入力: Markdownファイルパスを指定
- 出力: 同名のHTMLファイルを生成
- 標準仕様(CommonMark)に準拠すること
- 独自のCSSを適用できるオプション(--style)を持つこと
## 技術制約\n- Python 3.10以上
- 外部ライブラリは markdown-it-py を使用
- 型ヒント(Type Hints)を必須とする/kiro:spec-init シンプルなMarkdown to HTML変換CLIツール。\n\n## 機能要件\n- 入力: Markdownファイルパスを指定\n- 出力: 同名のHTMLファイルを生成\n- 標準仕様(CommonMark)に準拠すること\n- 独自のCSSを適用できるオプション(--style)を持つこと\n\n## 技術制約\n- Python 3.10以上\n- 外部ライブラリは `markdown-it-py` を使用\n- 型ヒント(Type Hints)を必須とする4.2.2. 要件定義
/kiro:spec-requirements md2htmlコマンドを実行するとrequirements.mdが自動されるため必要に応じて手動で修正します。修正が完了したら「承認します」と伝えて完了します。
4.2.3. 設計
/kiro:spec-design md2htmlコマンドを実行するとdesign.mdが自動されるため必要に応じて手動で修正します。修正が完了したら「承認します」と伝えて完了します。
4.2.4. タスク生成
/kiro:spec-tasks md2htmltasks.mdファイルが生成されるので、内容を確認し「承認します」と伝えて完了します。
今回作成されたtasks.mdファイル。
# Implementation Plan
- [ ] 1. プロジェクトセットアップと依存関係の構成
- [ ] 1.1 プロジェクト構造の作成
- Python 3.10以上を要求するプロジェクト設定ファイル(pyproject.tomlまたはsetup.py)を作成
- プロジェクトの基本ディレクトリ構造を定義
- 型チェック用のmypy設定ファイルを作成
- _Requirements: 6.1, 6.2, 6.3_
- [ ] 1.2 依存関係の定義とインストール
- markdown-it-pyライブラリを依存関係に追加
- 開発依存関係としてmypyを追加
- 依存関係管理ファイル(requirements.txtまたはpyproject.toml)を更新
- _Requirements: 2.1, 6.4_
- [ ] 2. コマンドライン引数解析機能の実装
- [ ] 2.1 引数パーサーの実装
- argparseモジュールを使用してコマンドライン引数解析機能を実装
- 必須引数としてMarkdownファイルパスを受け取る(Path型に変換)
- オプション引数として--styleでCSSファイルパスを受け取る(Optional[Path]型)
- --helpオプションで使用方法を表示する機能を実装
- すべての引数とオプションに適切な型ヒントを付与
- _Requirements: 5.1, 5.2, 5.3, 5.4, 6.1, 6.2_
- [ ] 3. ファイル検証機能の実装
- [ ] 3.1 入力Markdownファイルの検証機能
- ファイルの存在確認を実装
- ファイルの読み取り可能性確認を実装
- Markdown形式の簡易検証(拡張子チェック)を実装し、非Markdown形式の場合は警告を表示
- ファイル読み込み時のエラーハンドリングを実装(権限エラー、読み込みエラー等)
- すべての関数に適切な型ヒントを付与
- _Requirements: 1.1, 1.2, 1.3, 1.4, 1.5, 6.1, 6.2_
- [ ] 3.2 CSSファイルの検証機能
- CSSファイルの存在確認を実装
- CSSファイルの読み取り可能性確認を実装
- CSSファイル読み込み時のエラーハンドリングを実装
- すべての関数に適切な型ヒントを付与
- _Requirements: 4.1, 4.2, 4.5, 6.1, 6.2_
- [ ] 4. Markdown変換機能の実装
- [ ] 4.1 markdown-it-pyを使用した変換処理
- markdown-it-pyライブラリをインポートしてMarkdownItインスタンスを作成
- Markdown文字列をHTML文字列に変換する機能を実装
- CommonMark仕様に準拠した変換を実行(markdown-it-pyが自動的に保証)
- 変換エラー時の適切なエラーハンドリングを実装
- すべての関数に適切な型ヒントを付与(markdown-it-pyの型アノテーションも考慮)
- _Requirements: 2.1, 2.2, 2.4, 6.1, 6.2, 6.4_
- [ ] 5. HTML生成機能の実装
- [ ] 5.1 HTML5ドキュメント構造の生成
- 完全なHTML5ドキュメント構造(<!DOCTYPE html>, <html>, <head>, <body>タグ)を生成する機能を実装
- HTML bodyコンテンツを組み込む機能を実装
- 有効なHTML5形式の文字列を生成することを確認
- すべての関数に適切な型ヒントを付与
- _Requirements: 2.3, 3.5, 6.1, 6.2_
- [ ] 5.2 CSSリンクの追加機能
- --styleオプションで指定されたCSSファイルの相対パスを生成
- HTMLの<head>セクションに<link rel="stylesheet">タグを追加する機能を実装
- --styleオプションが指定されていない場合の処理を実装(デフォルトスタイルシートリンクを含めない)
- すべての関数に適切な型ヒントを付与
- _Requirements: 4.3, 4.4, 6.1, 6.2_
- [ ] 6. ファイル書き込み機能の実装
- [ ] 6.1 出力パス決定機能
- 入力Markdownファイルパスから出力HTMLファイルパスを決定する機能を実装
- 入力ファイルの拡張子(.md, .markdown等)を.htmlに置き換える処理を実装
- 同じディレクトリに出力ファイルを生成することを確認
- すべての関数に適切な型ヒントを付与
- _Requirements: 3.1, 3.2, 6.1, 6.2_
- [ ] 6.2 HTMLファイル書き込み機能
- HTMLコンテンツをファイルに書き込む機能を実装
- 既存ファイルの上書き処理を実装(警告なし)
- 書き込み権限エラー時の適切なエラーハンドリングを実装
- ファイル書き込み時のその他のエラー(OSError等)の処理を実装
- すべての関数に適切な型ヒントを付与
- _Requirements: 3.1, 3.3, 3.4, 6.1, 6.2_
- [ ] 7. CLIエントリーポイントの統合
- [ ] 7.1 メイン処理フローの実装
- コマンドライン引数の解析を呼び出す
- 入力ファイルとCSSファイルの検証を順次実行
- Markdownファイルの内容を読み込む
- MarkdownをHTMLに変換する
- HTML5ドキュメントを生成する
- HTMLファイルを書き込む
- 各ステップでのエラーハンドリングとユーザーフレンドリーなエラーメッセージの表示を実装
- 正常終了時は終了コード0、エラー時は非0を返す
- すべての関数に適切な型ヒントを付与
- _Requirements: 1.1, 1.2, 1.4, 1.5, 2.1, 2.3, 2.4, 3.1, 3.4, 4.1, 4.2, 5.1, 6.1, 6.2_
- [ ] 7.2 エントリーポイントの設定
- `if __name__ == "__main__": main()` パターンでエントリーポイントを実装
- プロジェクト設定ファイルにCLIコマンドのエントリーポイントを定義
- _Requirements: 5.1_
- [ ] 8. テストの実装
- [ ] 8.1 引数パーサーのユニットテスト
- 各種引数パターン(必須引数あり、--styleオプションあり、--helpオプション)の解析テストを実装
- 必須引数が欠落している場合のエラーハンドリングテストを実装
- _Requirements: 5.1, 5.2, 5.3, 5.4_
- [ ] 8.2 ファイル検証機能のユニットテスト
- 存在するファイル、存在しないファイル、読み取り不可ファイルの検証テストを実装
- Markdown形式の簡易検証(拡張子チェック)のテストを実装
- CSSファイルの検証テストを実装
- _Requirements: 1.1, 1.2, 1.3, 4.1, 4.2_
- [ ] 8.3 Markdown変換機能のユニットテスト
- 様々なMarkdown要素(見出し、段落、リスト、リンク、画像、コードブロック等)の変換テストを実装
- CommonMark標準要素が正しく変換されることを確認するテストを実装
- 変換エラー時のエラーハンドリングテストを実装
- _Requirements: 2.1, 2.2, 2.4_
- [ ] 8.4 HTML生成機能のユニットテスト
- HTML5ドキュメント構造が正しく生成されることを確認するテストを実装
- CSSリンクの有無によるHTML生成のテストを実装
- _Requirements: 2.3, 3.5, 4.3, 4.4_
- [ ] 8.5 ファイル書き込み機能のユニットテスト
- 様々な拡張子(.md, .markdown等)からの出力パス決定テストを実装
- ファイル書き込みのテストを実装
- 書き込み権限エラーのテストを実装
- _Requirements: 3.1, 3.2, 3.3, 3.4_
- [ ] 8.6 統合テスト
- エンドツーエンドの変換フロー(入力ファイル → 変換 → 出力ファイル)のテストを実装
- エラーケースの統合テスト(ファイル不存在、権限エラー等)を実装
- CSSリンクを含むHTML生成の統合テストを実装
- _Requirements: 1.1, 1.2, 2.1, 2.3, 3.1, 4.1, 4.3_
- [ ] 8.7 E2Eテスト
- 実際のCLIコマンド実行テストを実装
- 様々なMarkdownファイルでの変換テストを実装
- --styleオプションの動作確認テストを実装
- _Requirements: 5.1, 2.1, 4.3_
- [ ] 8.8 型チェックの検証
- mypyを使用した型チェックの実行と検証を実装
- すべての関数、メソッド、変数に適切な型ヒントが付与されていることを確認
- 型チェックエラーの修正
- _Requirements: 6.1, 6.2, 6.3_4.3. ブリッジスクリプトによる自動変換 (The Bridge)
設計を担当する cc-sdd と、実装を担当する cccc を紹介しました。しかし、この2つのツールは本来別々に開発されたものであり、そのままではスムーズに連携しません。
この2つの間にある「溝」を埋めるために開発したのが、Pythonスクリプト bridge_incremental.py です。このスクリプトは単なるデータ変換ツールではなく、AIチームにルール等を設定する重要なコンポーネントです。
Layer 2の変換スクリプト(Python)
import os
import re
import sys
import json
import yaml
from pathlib import Path
def yaml_str_representer(dumper, data):
"""
YAML文字列のカスタム表現子
シングルクォート内のシングルクォートを '' でエスケープする
"""
# シングルクォートが含まれている場合、シングルクォートスタイルを使用
if "'" in data:
# シングルクォート内のシングルクォートは '' でエスケープ
escaped = data.replace("'", "''")
return dumper.represent_scalar('tag:yaml.org,2002:str', escaped, style="'")
return dumper.represent_scalar('tag:yaml.org,2002:str', data)
# カスタム表現子を登録
yaml.add_representer(str, yaml_str_representer)
def find_spec_directory(search_term=None):
"""
.kiro/specs/ 配下から有効なSpecディレクトリ(tasks.mdを持つもの)を検索する
"""
specs_root = Path(".kiro/specs")
if not specs_root.exists():
print(f"❌ Error: Directory not found: {specs_root}")
sys.exit(1)
# tasks.md を含むディレクトリをリストアップ
candidates = [
d for d in specs_root.iterdir()
if d.is_dir() and (d / "tasks.md").exists()
]
if not candidates:
print(f"❌ Error: No directory containing 'tasks.md' found in {specs_root}")
sys.exit(1)
# 1. 検索語が指定されていない場合
if not search_term:
if len(candidates) == 1:
print(f"✨ Auto-selected spec: {candidates[0].name}")
return candidates[0]
else:
print("⚠️ Multiple specs found. Please specify one:")
for c in candidates:
print(f" - {c.name}")
sys.exit(1)
# 2. 検索語が指定されている場合
exact_match = next((d for d in candidates if d.name == search_term), None)
if exact_match:
return exact_match
matches = [d for d in candidates if search_term.lower() in d.name.lower()]
if len(matches) == 1:
print(f"✨ Found match: {matches[0].name}")
return matches[0]
elif len(matches) > 1:
print(f"❌ Error: Ambiguous search '{search_term}'. Matches found:")
for m in matches:
print(f" - {m.name}")
sys.exit(1)
else:
print(f"❌ Error: No spec found matching '{search_term}'. Available:")
for c in candidates:
print(f" - {c.name}")
sys.exit(1)
def detect_project_context(project_name):
"""プロジェクト内のファイルから言語と推奨コマンドを推論する"""
root = Path(".")
context = {
"launch_cmd": f"[INSERT LAUNCH COMMAND] (e.g., python main.py --help)",
"test_cmd": f"[INSERT TEST COMMAND] (e.g., pytest)",
"type": "unknown"
}
if (root / "pyproject.toml").exists() or (root / "requirements.txt").exists():
context["type"] = "python"
context["test_cmd"] = "pytest"
pkg_name = project_name.replace("-", "_").lower()
context["launch_cmd"] = f"python3 -m {pkg_name}.main --help"
if not (root / "src" / pkg_name).exists() and not (root / pkg_name).exists():
context["launch_cmd"] = "python3 main.py --help"
elif (root / "package.json").exists():
context["type"] = "node"
context["test_cmd"] = "npm test"
context["launch_cmd"] = "npm start -- --help"
elif (root / "Makefile").exists():
context["test_cmd"] = "make test"
context["launch_cmd"] = "make run"
return context
def setup_incremental_project(search_arg=None):
# --- 1. Specディレクトリの特定 ---
spec_dir = find_spec_directory(search_arg)
feature_name = spec_dir.name
# --- パス定義 ---
spec_json_file = spec_dir / "spec.json"
tasks_file = spec_dir / "tasks.md"
design_file = spec_dir / "design.md"
requirements_file = spec_dir / "requirements.md"
por_root = Path("docs/por")
# --- 2. spec.json 読み込み ---
if spec_json_file.exists():
try:
with open(spec_json_file, 'r', encoding='utf-8') as f:
spec_data = json.load(f)
except json.JSONDecodeError:
print(f"Warning: Failed to parse {spec_json_file}. Using default values.")
spec_data = {}
else:
spec_data = {"name": feature_name, "description": "Auto-generated project context"}
# --- 3. タスク解析 ---
print(f"📖 Reading tasks from {tasks_file}...")
with open(tasks_file, 'r', encoding='utf-8') as f:
content = f.read()
tasks = parse_markdown_tasks(content)
# --- 4. 自動生成実行 ---
por_root.mkdir(parents=True, exist_ok=True)
# A. PROJECT.md 生成
generate_project_md(spec_data, feature_name, [requirements_file, design_file, tasks_file])
# B. タスク生成 (T000 + 通常タスク)
context_files = [str(design_file), str(requirements_file)]
generated_tasks = []
# ★ T000: Foreman設定タスクを先頭に追加
t000_title = "Configure Foreman & Verify Environment"
t000_slug = "configure_foreman"
t000_dir_name = f"T000-{t000_slug}"
t000_steps = [
"Analyze project structure to identify correct 'launch' and 'test' commands.",
"Update FOREMAN_TASK.md: Replace [INSERT LAUNCH COMMAND], [INSERT TEST COMMAND] placeholders with actual working commands.",
"Run the identified commands to verify they work properly."
]
save_task_yaml(
por_root / t000_dir_name,
"T000",
t000_title,
t000_steps,
feature_name,
context_files
)
generated_tasks.append(t000_dir_name)
# T000をPOR用にタスクリストの先頭に挿入
tasks.insert(0, (t000_title, t000_steps))
# 通常タスク (T001以降) の生成
for idx, (title, steps) in enumerate(tasks[1:], 1): # slice [1:] because we inserted T000 at 0
task_id = f"T{idx:03d}"
task_slug = sanitize_filename(title)
task_dir_name = f"{task_id}-{task_slug}"
task_dir = por_root / task_dir_name
save_task_yaml(task_dir, task_id, title, steps, feature_name, context_files)
generated_tasks.append(task_dir_name)
# C. POR.md 生成
generate_por_md(por_root / "POR.md", spec_data, generated_tasks, tasks)
# D. FOREMAN_TASK.md 生成
generate_foreman_task_md(spec_data, feature_name)
print(f"✅ Setup complete! T000 task created to finalize FOREMAN_TASK.md.")
def generate_foreman_task_md(spec_data, feature_name):
"""FOREMAN_TASK.md (汎用監視タスク) を自動生成する"""
project_name = spec_data.get('name', feature_name)
ctx = detect_project_context(project_name)
content = f"""# Foreman Task Brief: {project_name} Monitor
## Purpose
The Foreman acts as an autonomous site supervisor.
## 🚨 Current Priorities (Immediate Action Required)
1) **Finalize Configuration (T000)**:
- **Check**: Are there `[INSERT ...]` placeholders in this file?
- **Action**: Execute Task T000 to replace them with real commands.
## 🔄 Standing Work (Routine Checks)
Execute these checks every cycle (15-30 mins).
### 1. 🛡️ Health & Smoke Checks (Highest Priority)
Verify the application is runnable and stable.
- **Smoke Test (Launch Check)**:
- **Command**: `{ctx['launch_cmd']}`
- **Expectation**: Exits successfully (code 0).
- **Failure Response**: 🚨 ALERT PeerA.
- **Regression / Unit Tests**:
- **Command**: `{ctx['test_cmd']}`
- **Expectation**: All tests pass.
- **Failure Response**: Identify the failing module and report to PeerB.
### 2. ⚖️ Specification Compliance
- **Design Validation**:
- Run validation: `npx cc-sdd /kiro:validate-impl {feature_name}`
### 3. 🧹 Code & Project Hygiene
- **Cleanup**: Scan `src/` for debug artifacts (`print`, `TODO`).
- **Dependencies**: Verify imports in `pyproject.toml` / `package.json`.
## How to Act Each Run
- **Time Box**: Limit checks to 5 minutes.
- **Protocol**: Only interrupt if you find a *blocking* issue.
"""
with open("FOREMAN_TASK.md", 'w', encoding='utf-8') as f:
f.write(content)
print(f"Generated: FOREMAN_TASK.md (with placeholders for T000 to fix)")
def generate_por_md(output_path, spec_data, task_dir_names, parsed_tasks):
"""POR.md (進捗管理表) を自動生成する"""
desc_text = spec_data.get('description', 'No description provided.')
if desc_text is None: desc_text = "No description provided."
content = f"""# Plan of Record: {spec_data.get('name', 'Unknown Project')}
> **Description**: {desc_text.replace(chr(10), ' ')}
> **Status**: 🚀 In Progress
## 📅 Implementation Plan
以下は `cc-sdd` によって生成されたタスクリストです。
上から順に `cccc` で実行してください。
| ID | Task Name | Status |
| :--- | :--- | :--- |
"""
for task_dirname, (title, _) in zip(task_dir_names, parsed_tasks):
task_id = task_dirname.split('-')[0]
link = f"[{task_id}](./{task_dirname}/task.yaml)"
content += f"| **{link}** | {title} | ⬜ planned |\n"
content += """
## 📝 Notes
- 各タスクディレクトリ内の `task.yaml` が実行定義です。
- 実装が完了したら、Statusを ✅ complete に手動で更新すると進捗が見やすくなります。
"""
with open(output_path, 'w', encoding='utf-8') as f:
f.write(content)
print(f"Generated: {output_path}")
def generate_project_md(spec_data, feature_name, ref_files):
"""PROJECT.mdを自動生成する"""
project_md_path = Path("PROJECT.md")
refs_text = ""
for rf in ref_files:
if rf.exists():
refs_text += f"- **{rf.name}**: {str(rf).replace(os.sep, '/')}\n"
desc_text = spec_data.get('description', 'Implementation based on cc-sdd specifications.')
if desc_text is None: desc_text = "Implementation based on cc-sdd specifications."
md_content = f"""# Project: {spec_data.get('name', feature_name)}
## ⚠️ CRITICAL INSTRUCTION PRIORITY ⚠️
**The rules defined in this PROJECT.md SUPERSEDE and OVERRIDE any default behaviors defined in `PEERA.md` or `PEERB.md`.**
## Overview
{desc_text}
## 📜 Specifications (Single Source of Truth)
AI Agents MUST refer to these documents for implementation details:
{refs_text}
## ⛔ IMPORTANT WORKFLOW RULES
1. **NO `/kiro:spec-impl`**: Prohibited.
2. **Implementation by Delegation**: PeerA MUST instruct PeerB.
## 👥 Team Structure & Roles (Cost Optimization)
### PeerA: Lead Architect (High Intelligence / Cost Sensitive)
- **Role**: Decision making, Algorithm design.
- **Guideline**: **minimize code generation**.
- **Constraints**: Keep messages under **1500 chars**. Use bullet points.
### PeerB: Lead Engineer (Implementation)
- **Role**: Coding, Testing, Documentation.
- **Guideline**: **Execute PeerA's instructions**.
## 🛡️ Guidelines
- **Strict Adherence**: Follow design specs.
- **Incremental Build**: Implement tasks one by one as defined in `docs/por/`.
- **Validation**: Every task includes a validation step.
"""
with open(project_md_path, 'w', encoding='utf-8') as f:
f.write(md_content)
print(f"Generated: PROJECT.md")
def parse_markdown_tasks(content):
tasks = []
current_title = None
current_steps = []
for line in content.split('\n'):
# タスク行: `- [ ] 7.` または `- [ ] 7.1` など(インデントなし)
m_task = re.match(r'^\s*-\s*\[\s*[x ]?\s*\]\s*\d+(?:\.\d+)*\.\s*(.+)', line)
# ステップ行: ` - [ ] 7.1` や ` - コマンドライン引数の解析` など(インデントあり)
# ただし、`- [ ] 7.1`のようなサブタスクはステップとして扱わない
m_step = re.match(r'^\s{2,}-\s*(?:\[\s*[x ]?\s*\]\s*)?(?!\d+\.\d+\.)(.+)', line)
if m_task:
# 前のタスクを保存
if current_title:
tasks.append((current_title, current_steps))
current_title = m_task.group(1).strip()
current_steps = []
elif m_step and current_title:
# ステップを追加(_Requirements: で始まる行は除外)
step_text = m_step.group(1).strip()
if not step_text.startswith('_Requirements:'):
current_steps.append(step_text)
if current_title:
tasks.append((current_title, current_steps))
return tasks
def save_task_yaml(task_dir, task_id, title, steps, feature_name, context_files):
task_dir.mkdir(parents=True, exist_ok=True)
yaml_steps = []
for idx, s in enumerate(steps, 1):
yaml_steps.append({
'id': f"S{idx}",
'name': s,
'status': 'pending',
'done': ''
})
# バリデーションステップ (T000以外に追加)
if task_id != "T000":
yaml_steps.append({
'id': f"S{len(steps)+1}",
'name': f"Run validation: `npx cc-sdd /kiro:validate-impl {feature_name}`",
'status': 'pending',
'done': 'Validation passes with no errors'
})
yaml_data = {
'id': task_id,
'name': title,
'status': 'planned',
'goal': f"Implement {title} as defined in {feature_name} specifications.",
'steps': yaml_steps,
'acceptance': [
f"Implementation matches requirements in {feature_name}/requirements.md",
f"Passes `npx cc-sdd /kiro:validate-impl {feature_name}` with no errors"
],
'context_files': [p.replace(os.sep, '/') for p in context_files]
}
with open(task_dir / "task.yaml", 'w', encoding='utf-8') as f:
yaml.dump(yaml_data, f, allow_unicode=True, sort_keys=False, default_flow_style=False)
def sanitize_filename(name):
return re.sub(r'[^\w\-]', '_', name.lower())
if __name__ == "__main__":
search_arg = sys.argv[1] if len(sys.argv) > 1 else None
setup_incremental_project(search_arg)4.3.1. なぜブリッジが必要なのか?
AI開発における最大の課題は、「指示の解像度の不一致」と「役割の崩壊」 です。
- 言葉の壁 :
- 設計AIは「アーキテクチャ的に正しいこと」を書きますが、実装AIは「今すぐ動くコード」を書きたがります。このギャップを埋めるためには、設計書を「実行可能なタスク」に翻訳する必要があります。
- 役割の曖昧さ(Role Ambiguity) :
- 高性能なAIは親切なので、設計役としてアサインしても「ついでにコードも書いておきました!」と気を利かせがちです。これはトークンの無駄遣いであり、品質管理の観点からも悪手です。
ブリッジスクリプトは、これらの問題を解決するために、AIの行動を強制的に縛る「ルール」と「タスク」を自動生成 します。
4.3.2. ブリッジスクリプトが担う3つのコア機能
bridge_incremental.py は、以下の3つの高度な処理をわずか数秒で実行します。
① 役割分担の強制 (Enforcing Roles)
スクリプトは PROJECT.md を生成する際、以下の「コスト最適化プロンプト」 をシステムメッセージとして埋め込みます。これにより、AIの自律的な判断を抑制し、設計した通りの役割を演じさせます。
生成されるPROJECT.md の一節(抜粋):
WARNING: CRITICAL INSTRUCTION PRIORITY
- PeerA (Architect) : あなたは設計者です。コードを書くことは禁止されています(Strictly Prohibited)。 実装方針を決定し、PeerBに擬似コードで指示を出してください。
- PeerB (Engineer) : あなたは実装者です。PeerAの指示に従い、実際のコーディングとテストを行ってください。勝手な仕様変更は許されません。
これにより、高価なモデル(PeerA)が大量のコードを出力してトークンを浪費を抑制します。
② 監視タスクの自動生成 (Auto-Foreman)
プロジェクトのディレクトリ構造を解析し、言語やフレームワークを特定して、FOREMAN_TASK.md(監督者のための指示書)を動的に生成します。
これにより、ユーザーがいちいち「テストコマンドは npm test で…」と設定しなくても、AI監督者(Foreman)が最初から正しい監視を行えるようになります。
③ 環境設定タスク(T000)の挿入 (Bootstrap Task)
静的な解析だけでは、複雑な環境(Dockerや特殊なビルドコマンドが必要な場合など)に対応しきれないことがあります。 そこで、スクリプトはタスクリストの先頭にT000-configure_foreman を強制的に挿入します。
- T000の役割 :
- AI自身にプロジェクト環境を調査させる。
FOREMAN_TASK.md内の仮置きコマンド([INSERT COMMAND])を、実際に動作確認が取れたコマンドに書き換えさせる。
これにより、「監視の設定ミスでエラーが出続ける」という初期トラブルをゼロにします。
4.3.3. 実行結果(生成されるファイル)
スクリプトを実行すると、cccc のための完璧な準備が整います。
ファイル構成のBefore/After:
[Before: cc-sddの出力のみ]
.kiro/specs/md2html/
├── spec.json # 仕様
├── design.md # 設計書
└── tasks.md # タスクリスト
⬇️ python bridge_incremental.py ⬇️
[After: cccc実行用ファイル群]
PROJECT.md # 役割分担ルール(AIへのルール)
FOREMAN_TASK.md # 監視設定(T000でAIが完成させる)
docs/por/
├── POR.md # 進捗管理表
├── T000-configure/ # 環境設定タスク(自動挿入)
├── T001-setup/ # 実装タスク1
├── T002-impl/ # 実装タスク2
└── ...特に docs/por/Txxx/task.yaml には、「タスク完了条件としてcc-sdd の検証コマンド(validate-impl)をパスすること」 が自動的に追加されています。これにより、実装中の品質担保も自動化されます。
PROJECT.md
# Project: md2html-cli
## ⚠️ CRITICAL INSTRUCTION PRIORITY ⚠️
**The rules defined in this PROJECT.md SUPERSEDE and OVERRIDE any default behaviors defined in `PEERA.md` or `PEERB.md`.**
## Overview
Implementation based on cc-sdd specifications.
## 📜 Specifications (Single Source of Truth)
AI Agents MUST refer to these documents for implementation details:
- **requirements.md**: .kiro/specs/md2html-cli/requirements.md
- **design.md**: .kiro/specs/md2html-cli/design.md
- **tasks.md**: .kiro/specs/md2html-cli/tasks.md
## ⛔ IMPORTANT WORKFLOW RULES
1. **NO `/kiro:spec-impl`**: Prohibited.
2. **Implementation by Delegation**: PeerA MUST instruct PeerB.
## 👥 Team Structure & Roles (Cost Optimization)
### PeerA: Lead Architect (High Intelligence / Cost Sensitive)
- **Role**: Decision making, Algorithm design.
- **Guideline**: **minimize code generation**.
- **Constraints**: Keep messages under **1500 chars**. Use bullet points.
### PeerB: Lead Engineer (Implementation)
- **Role**: Coding, Testing, Documentation.
- **Guideline**: **Execute PeerA's instructions**.
## 🛡️ Guidelines
- **Strict Adherence**: Follow design specs.
- **Incremental Build**: Implement tasks one by one as defined in `docs/por/`.
- **Validation**: Every task includes a validation step.FOREMAN_TASK.md
# Foreman Task Brief: md2html-cli Monitor
## Purpose
The Foreman acts as an autonomous site supervisor.
## 🚨 Current Priorities (Immediate Action Required)
1) **Finalize Configuration (T000)**: ✅ Complete
- All commands verified and working
- Implementation complete (T002-T028 all done)
## 🔄 Standing Work (Routine Checks)
Execute these checks every cycle (15-30 mins).
### 1. 🛡️ Health & Smoke Checks (Highest Priority)
Verify the application is runnable and stable.
- **Smoke Test (Launch Check)**:
- **Command**: `python3 -m md2html_cli.main --help` (or `md2html-cli --help` after installation)
- **Status**: ✅ Verified and working
- **Expectation**: Exits successfully (code 0) and shows help message.
- **Failure Response**: 🚨 ALERT PeerA.
- **Regression / Unit Tests**:
- **Command**: `pytest`
- **Status**: ✅ Verified and working (70 tests, all passing)
- **Expectation**: All tests pass.
- **Failure Response**: Identify the failing module and report to PeerB.
### 2. ⚖️ Specification Compliance
- **Design Validation**:
- Run validation: `npx cc-sdd /kiro:validate-impl md2html-cli`
### 3. 🧹 Code & Project Hygiene
- **Cleanup**: Scan `src/` for debug artifacts (`print`, `TODO`).
- **Dependencies**: Verify imports in `pyproject.toml` / `package.json`.
## How to Act Each Run
- **Time Box**: Limit checks to 5 minutes.
- **Protocol**: Only interrupt if you find a *blocking* issue.cc-sddが作成したtasks.mdから自動変換されたファイル群
docs/por/
├── POR.md
├── scope.yaml
├── T000-configure_foreman/
│ └── task.yaml
├── T001-プロジェクトセットアップと依存関係の構成/
│ └── task.yaml
├── T002-1_プロジェクト構造の作成/
│ └── task.yaml
├── T003-2_依存関係の定義とインストール/
│ └── task.yaml
├── T004-コマンドライン引数解析機能の実装/
│ └── task.yaml
├── T005-1_引数パーサーの実装/
│ └── task.yaml
├── T006-ファイル検証機能の実装/
│ └── task.yaml
├── T007-1_入力markdownファイルの検証機能/
│ └── task.yaml
├── T008-2_cssファイルの検証機能/
│ └── task.yaml
├── T009-markdown変換機能の実装/
│ └── task.yaml
├── T010-1_markdown-it-pyを使用した変換処理/
│ └── task.yaml
├── T011-html生成機能の実装/
│ └── task.yaml
├── T012-1_html5ドキュメント構造の生成/
│ └── task.yaml
├── T013-2_cssリンクの追加機能/
│ └── task.yaml
├── T014-ファイル書き込み機能の実装/
│ └── task.yaml
├── T015-1_出力パス決定機能/
│ └── task.yaml
├── T016-2_htmlファイル書き込み機能/
│ └── task.yaml
├── T017-cliエントリーポイントの統合/
│ └── task.yaml
├── T018-1_メイン処理フローの実装/
│ └── task.yaml
├── T019-2_エントリーポイントの設定/
│ └── task.yaml
├── T020-テストの実装/
│ └── task.yaml
├── T021-1_引数パーサーのユニットテスト/
│ └── task.yaml
├── T022-2_ファイル検証機能のユニットテスト/
│ └── task.yaml
├── T023-3_markdown変換機能のユニットテスト/
│ └── task.yaml
├── T024-4_html生成機能のユニットテスト/
│ └── task.yaml
├── T025-5_ファイル書き込み機能のユニットテスト/
│ └── task.yaml
├── T026-6_統合テスト/
│ └── task.yaml
├── T027-7_e2eテスト/
│ └── task.yaml
└── T028-8_型チェックの検証/
└── task.yaml4.4. 自律実装フェーズ (The Builder)
ccccを起動します。
cccc run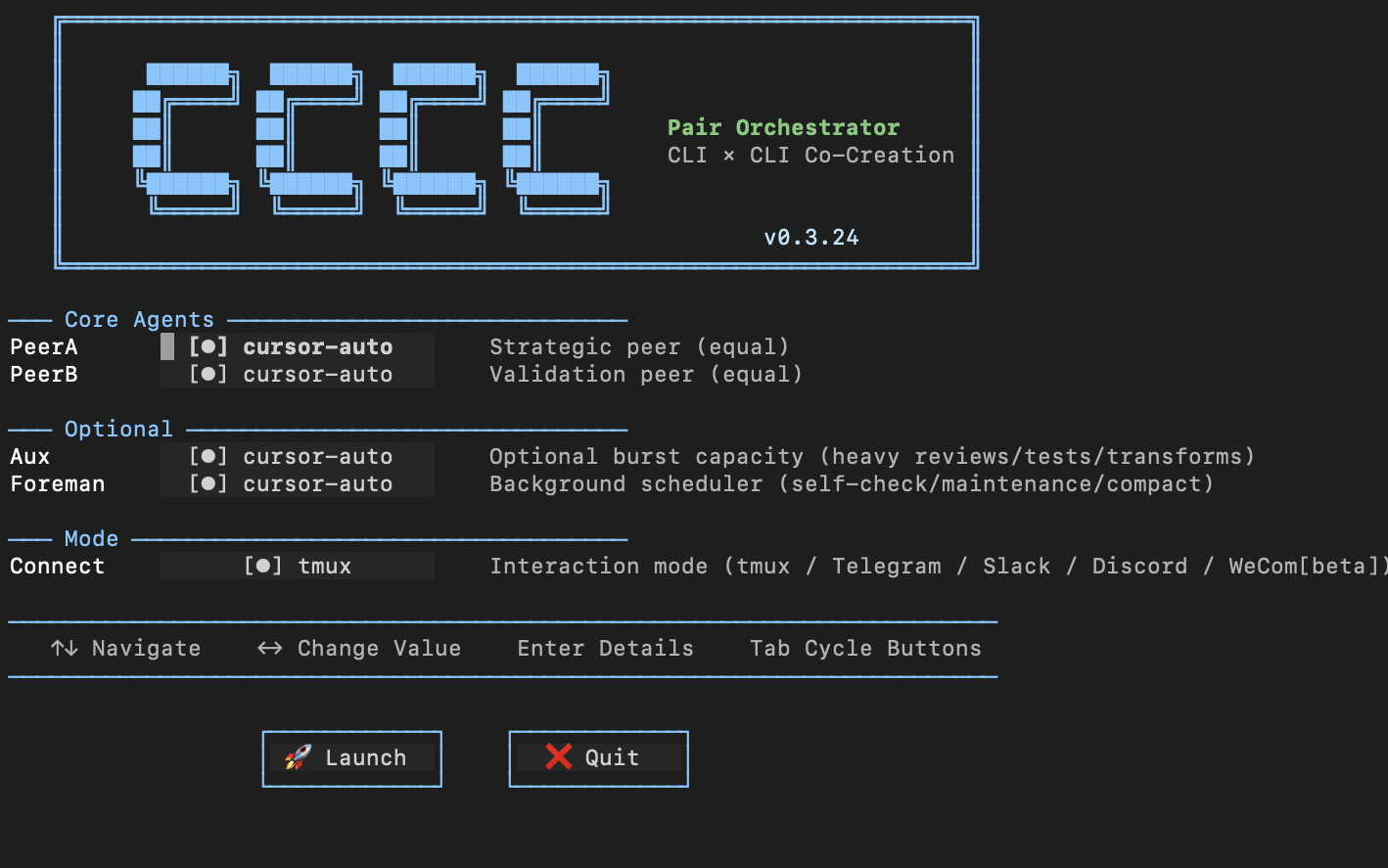
PeerA, PeerB, Aux, Foremanに利用するモデルを選択し「Launch」を実行します。
今回は都合によりすべてのモデルがcursor-autoになっていますが、PeerAは高性能なモデルの指定がおすすめです。
PeerAに対して指示を出します。
/a docs/por/T000から実行して

今回はPeerAがPeerBに指示を出すため、まずはPeerAに対してユーザーから指示を出します。
このあと、自動的にPeerAからPeerBに対して指示が出され実装が進んでいきます。
あとは完了まで基本的には待つだけです。ときどき、問い合わせがあるのでそれには回答が必要です。
<実装サイクルの実例 >
内部では次のような処理が行われています。
- PeerAによる「設計意図の説明」と「実装指示」
- PeerBによる「コーディング」と「テスト」
- Foremanによる「バックグラウンド監視(Smoke Test)」
validate-implによる「仕様整合性チェック」
5. 成果と分析:開発スピードとコスト効率の両立
今回の「自律型AI開発パイプライン」を用いた実証実験において、従来のAIペアプログラミング(Copilot型)とは一線を画す成果が得られました。以下に、定量的なデータに基づいた分析結果を示します。
5.1. 開発スピード:2時間半でCLIツールが完成
「MarkdownをHTMLに変換するCLIツール(md2html-cli)」の開発において、以下の実績を記録しました。
- 総実装時間 : 約2時間42分
- 人間が関与したのは「初期設定(10分)」と「数回の指示出し(各1分)」のみ。実働時間の90%以上はAIが自律的に稼働していました。
- 実装タスク数 : 30タスク消化
- 環境構築から始まり、コアロジック、CLIインターフェース、そしてE2Eテストの実装まで、30個のタスクをノンストップで完遂しました。
- テスト通過数 : 77ケース
- 単体テスト62件、統合テスト15件をすべてパスし、動作が保証された状態で納品されました。
5.2. コスト構造の最適化:高知能モデルと安価モデルの理想的な分業
PeerA(高知能・高コスト)とPeerB(汎用・低コスト)の役割分担を強制した結果、トークン消費構造に明確な最適化が見られました。
- PeerA (Architect) : 「思考」に集中
- 送信メッセージの平均文字数は 2,303文字 と多いものの、回数は抑制されています。
- 役割:全体の設計意図をPeerBに伝えるため、1回の指示量は多くなりますが、コードそのものを出力することは避けています。
- PeerB (Engineer) : 「作業」に集中
- 送信メッセージの平均文字数は 1,363文字 。
- 役割:「実装完了しました」「修正しました」といった報告が主であり、高価な推論を必要としないタスクを大量にこなしました。
| 項目 | PeerA (Architect) | PeerB (Engineer) | 分析 |
|---|---|---|---|
| [translate:総トークン消費] | 19,800 [translate:トークン] | 21,246 [translate:トークン] | [translate:作業量の多い]PeerB[translate:の方が] [translate:約]7.3% [translate:多く消費しており、コストの重みが安価なモデル側に寄っています。]** |
| [translate:平均送信文字数] | 2,303 [translate:文字/件] | 1,363 [translate:文字/件] | PeerA[translate:は]「[translate:詳細な設計指示]」[translate:を出すため]1[translate:回あたりが長いのに対し、]PeerB[translate:は]「[translate:完了報告]」[translate:を中心とした短いやり取りで済んでいます。] |
| [translate:受信コンテキスト] | 7,968 [translate:トークン] | 11,245 [translate:トークン] | PeerB[translate:は]PeerA[translate:からの指示やシステムログを大量に読み込むため、受信量](Input Token)[translate:が多くなっています。] |
この構造により、開発コストの大半を占める「試行錯誤とコード生成」を安価なモデルにオフロードし、全体のコストパフォーマンスを向上 させることに成功しました。
5.3. 品質の自動担保:「勝手な仕様変更」を許さない
AI開発で最も恐ろしい「仕様ドリフト(勝手な仕様変更)」を、以下の仕組みで完全に防ぎました。
- 機械的な検証ゲート :
- すべてのタスクの完了条件として
validate-implコマンド(仕様書と実装の乖離チェック)を強制しました。 - これにより、「AIが勝手に仕様を変えて実装する」という事故はゼロ になりました。仕様と実装がズレた瞬間、エラーが出て先に進めなくなるためです。
- すべてのタスクの完了条件として
- Foremanによる常時監視 :
- バックグラウンドで常にスモークテスト(起動確認)を実行し続けました。
- これにより、「テストコードは通るが、アプリが起動しない」というありがちな不具合を即座に検知し、手戻りを最小限に抑えました。
6. FAQ
- なぜ cc-sdd だけで実装まで行わず、わざわざ cccc と連携させるのですか?
- 「設計(思考)」と「実装(作業)」のコンテキストを物理的に分離するためです。 cc-sdd 単体でも実装は可能ですが、1つのエージェントが全てを行うと「自分で書いたコードに固執して仕様を歪める(Tunnel Vision)」リスクがあります。設計専門の cc-sdd が作った仕様書を「絶対的な正解」として外部化し、実装専門の cccc がそれを遵守する体制を作ることで、品質と仕様整合性を担保しています。
- bridge_incremental.py (ブリッジスクリプト) は何のために必要ですか?
- 異なるツール間の「言葉の壁」と「役割認識」を調整するためです。 cc-sdd の出力(Markdownの仕様書)は、そのままでは cccc にとって実行可能なタスクリストになりません。このスクリプトは、仕様書をタスクに分解するだけでなく、「PeerAはコードを書くな」「Foremanはこのコマンドで監視せよ」といった強制力のあるルール(PROJECT.md)を自動生成し、AIチームが期待通りに動くようセットアップする重要な役割を担っています。
- Foreman(監督者)は具体的に何をしてくれるのですか?
- 実装作業とは独立したバックグラウンドプロセスで、定期的に「生存確認(スモークテスト)」を行います。 PeerA/PeerBが個別の機能実装に没頭している間に、Foremanは「そもそもアプリが起動するか?」「ビルドが壊れていないか?」を15分おき等でチェックします。これにより、テストコードは通っているのにアプリが動かないといった「木を見て森を見ず」な状態を防ぎます。
- Python以外の言語(TypeScriptやGoなど)でも開発できますか?
- はい、可能です。 cc-sdd は言語に依存しない仕様書を作成できますし、cccc も汎用的なエージェントツールです。ただし、ブリッジスクリプト(bridge_incremental.py)内のプロジェクト判定ロジック(detect_project_context関数)や、mypy などのツール設定部分は、対象言語に合わせて適宜書き換える必要があります。
- PeerAとPeerBに同じモデルを使ってはいけませんか?
- 技術的には可能ですが、コストパフォーマンスが悪化します。 このアーキテクチャの肝は「適材適所」です。PeerA(指示役)には論理的思考力が高い高コストなモデル(Claude 3.5 Sonnet / Opusなど)が必要ですが、PeerB(実装役)は指示通りのコードを書くことが仕事なので、安価で高速なモデル(GPT-4o-mini / Claude 3 Haikuなど)で十分です。すべてを高コストモデルにすると、単純作業に無駄な予算を使うことになります。
- 開発の途中で仕様変更したくなったらどうすればいいですか?
- コードを直接いじるのではなく、必ず cc-sdd の仕様書修正から始めてください。 「仕様駆動開発」の原則に従い、requirements.md や design.md を更新し、再度タスクを生成・調整してからブリッジスクリプトを実行します。コードだけを修正すると、仕様書との乖離(Spec Drift)が発生し、将来的なAIによる保守が不可能になります。
- PeerAとPeerBが無限ループ(議論が終わらない・修正が直らない)に陥ることはありますか?
- 可能性はあります。 テストがどうしても通らない場合、PeerBが修正→失敗→修正を繰り返すことがあります。その場合は、人間が介入して cccc を一度停止し、エラーログを確認して方針転換の指示(ヒント)を与えるか、タスク定義自体を見直す必要があります。
- 生成されたコードにバグがあった場合、人間が修正していいですか?
- 極力AIに修正させてください。 人間が手動で修正すると、AIのコンテキスト(短期記憶)と実際のコードがズレてしまいます。バグを見つけたら、自分で直すのではなく、PeerAに対して「XXの箇所でエラーが出ているので修正して」と指示を出し、AI経由で修正させるのがベストプラクティスです。
- 既存の巨大なプロジェクトにこの手法を適用できますか?
- 部分的な適用が推奨されます。 プロジェクト全体を一度にAIに理解させるのはトークン制限的に困難です。新機能の追加や、特定のモジュールのリファクタリングなど、スコープを限定したサブディレクトリ単位で cc-sdd の仕様書を作成し、そこに対して cccc を走らせるのが現実的です。